
Di Tyler Bell, Vicepresidente senior Prodotti
Man mano che le aziende adotteranno sistemi di IA generativa, come i modelli linguistici di grandi dimensioni (LLM¹), per i vantaggi in termini di efficienza che questi possono offrire, una serie di tecnologie obsolete diventerà sempre più superata. Nel settore televisivo, gli LLM potenzieranno – e alla fine sostituiranno – i database tradizionali e le funzioni di ricerca rudimentali. Col tempo, diventeranno i motori predefiniti per offrire esperienze di intrattenimento di nuova generazione.
Questo cambiamento avrà un impatto rivoluzionario sui consumatori. Il pubblico televisivo, ad esempio, non dovrà più limitarsi a semplici ricerche quando cerca qualcosa da guardare.
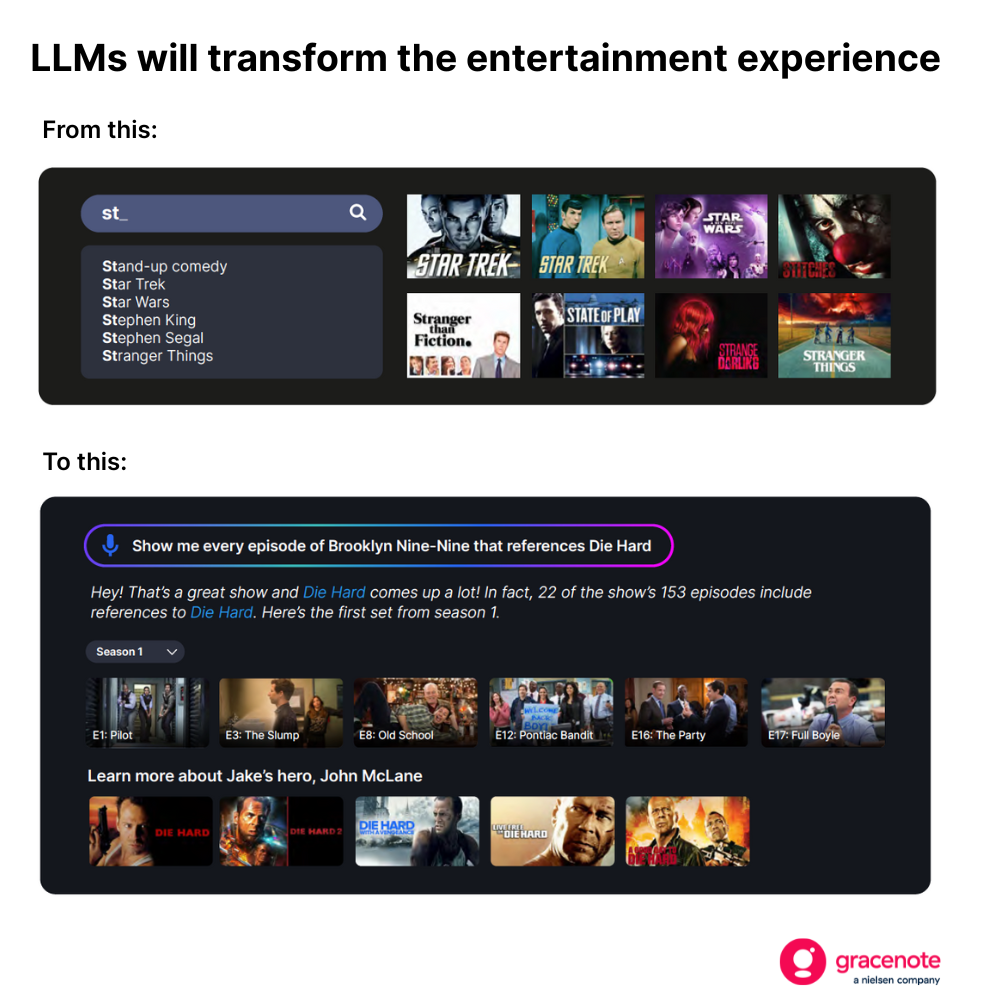
Ma per creare questo tipo di esperienza — in grado di fornire risultati aggiornati, accurati e pertinenti — non basta un modello di linguaggio di grandi dimensioni (LLM) ben addestrato.
Questo perché i modelli di linguaggio di grandi dimensioni (LLM) non sono banche dati complete. Sono motori predittivi che generano risposte sulla base di schemi appresi dai dati utilizzati per il loro addestramento. E troppo spesso quei dati sono viziati.
Uno studio del 2022 condotto da ricercatori dell’Università della California del Sud ha rilevato che fino al 38% dei dati “oggettivi” di senso comune utilizzati in due distinti database di intelligenza artificiale era viziato da pregiudizi. In altre parole, più di un terzo dei dati di base di quei sistemi era inaccurato fin dall’inizio.

I modelli di linguaggio di grandi dimensioni (LLM) hanno difficoltà anche con compiti relativamente semplici. Nel marzo 2025, uno studio della Columbia Journalism Review ha rilevato che otto strumenti di IA generativa hanno registrato un tasso di errore complessivo del 60% quando è stato chiesto loro di associare un estratto di un articolo di cronaca al titolo corrispondente, all’editore originale, alla data di pubblicazione e all’URL. In confronto, una ricerca tradizionale su Google ha restituito le fonti già nei primi tre risultati.
I limiti dei modelli di linguaggio di grandi dimensioni (LLM) sono ben noti ed esistono diverse tecniche per ridurre le allucinazioni e migliorare la pertinenza contestuale. Pochi metterebbero in discussione l'utilità delgrounding2. Tuttavia, collegare un LLM a dati imprecisi per il grounding è altrettanto problematico quanto utilizzare dati errati per addestrarlo.
Il punto fondamentale è che i dati di scarsa qualità rappresentano una minaccia concreta. I modelli di linguaggio di grandi dimensioni (LLM) sono strumenti potenti, ma la loro efficacia dipende interamente dalla qualità delle informazioni a cui hanno accesso.
L'adozione dell'LLM nella CTV
È improbabile che il passaggio ai modelli di linguaggio di grandi dimensioni avvenga con un unico cambiamento radicale. Si verificherà invece «gradualmente, poi all’improvviso», come descrive Mike Campbell, personaggio di Hemingway, la propria bancarotta in *Il sole sorgerà ancora*.
I modelli di linguaggio di grandi dimensioni (LLM) sono ancora una tecnologia relativamente nuova. Presentano dei limiti, implicano problemi di latenza e comportano costi che le organizzazioni devono comprendere prima di implementarli nelle interfacce di ricerca rivolte ai consumatori. La sfida fondamentale, tuttavia, riguarda i dati.
La maggior parte delle interfacce CTV si basa su data lake contenenti metadati eterogenei provenienti da diverse fonti, che devono essere armonizzati e normalizzati prima di essere indicizzati e ottimizzati per la ricerca. Questo processo richiede il download preventivo di grandi set di dati, il loro trattamento attraverso complesse pipeline di acquisizione e il loro aggiornamento continuo per garantire l'attualità delle informazioni.
I modelli di linguaggio di grandi dimensioni (LLM), al contrario, eccellono nell'interpretazione e nella sintesi di dati provenienti da più fonti in tempo reale, riducendo potenzialmente – o addirittura eliminando – la necessità dei tradizionali data lake e delle relative infrastrutture.
Allo stesso tempo, i modelli di linguaggio di grandi dimensioni (LLM) offrono nuove funzionalità e un enorme potenziale alla CTV, che sarebbero altrimenti impossibili da realizzare con la tecnologia attuale. Ad esempio, i modelli LLM possono riscrivere o arricchire in modo dinamico la descrizione di un film o di un episodio per renderla più pertinente per i singoli utenti.
Ad esempio, dopo che uno spettatore ha visto *Le ali della libertà*, un modello LLM potrebbe consigliargli *Il miglio verde* con una descrizione personalizzata: «È un adattamento di Stephen King che parla di speranza, ambientato in una prigione, con una profondità emotiva simile a quella de *Le ali della libertà*, che ti è piaciuto molto in precedenza».
Questo tipo di raccomandazione contestuale rappresenta un notevole miglioramento rispetto ai suggerimenti generici del tipo «Poiché hai guardato...». I modelli di linguaggio di grandi dimensioni (LLM) possono applicare questo approccio a tutti i titoli presenti in un catalogo.
Nel breve termine, i modelli di linguaggio di grandi dimensioni (LLM) verranno probabilmente introdotti come complemento alle tecnologie esistenti, occupandosi di richieste complesse o di tipo colloquiale che i sistemi tradizionali non sono in grado di gestire. Col tempo, alcune organizzazioni sostituiranno completamente le loro infrastrutture legacy. Alla fine, saranno i modelli di linguaggio di grandi dimensioni a fare la differenza.
La frammentazione ha reso più complessa l'esperienza di visione televisiva
Nonostante l'ampia offerta di programmi disponibili, la frammentazione della distribuzione video ha reso più difficile, anziché più facile, la ricerca dei contenuti, andando a discapito dei fornitori di contenuti.
Infatti, secondo un recente sondaggio di settore, quasi il 50% dei telespettatori statunitensi prenderebbe in considerazione l'idea di disdire un servizio di streaming perché non riesce a trovare nulla da guardare. Tra il pubblico di età compresa tra i 25 e i 34 anni, tale percentuale sale al 58%.

Una maggiore quantità di contenuti non si traduce necessariamente in un aumentodel tempo di visione³. In pratica, una scelta troppo ampia può indurre gli spettatori ad abbandonare del tutto la ricerca e a dedicarsi ad altro.
È qui che i modelli di linguaggio di grandi dimensioni (LLM) possono essere d'aiuto, ma solo se si basano sui dati giusti.
Per le piattaforme CTV, disporre di dati affidabili e conformi agli standard del settore nel campo dell'intrattenimento costituisce una base ideale. Oltre a fornire informazioni standardizzate sui programmi, tali dati includono palinsesti televisivi aggiornati, fondamentali per gli spettatori che sanno cosa vogliono guardare ma non sanno dove trovarlo. Ciò è particolarmente importante per gli eventi sportivi in diretta.

Con il passare del tempo, i modelli di linguaggio di grandi dimensioni (LLM) offriranno agli spettatori esperienze televisive rivoluzionarie. Cerchi i migliori film horror del 1985 in base agli incassi al botteghino? Nessun problema. Vuoi dei consigli sui migliori film sul calcio in base alle recensioni della critica dopo aver visto i Mondiali? Facile. Stai cercando di capire su quale piattaforma è disponibile una determinata partita, serie TV o film? Ci pensiamo noi.
Le aspettative dei consumatori riguardo al modo in cui interagiscono con la tecnologia continuano a crescere, e le piattaforme CTV hanno l'opportunità di anticipare i tempi. I modelli di linguaggio di grandi dimensioni (LLM) possono mantenere questa promessa, ma solo se basati su dati affidabili e aggiornati. Poiché i telespettatori rivalutano costantemente dove investono il proprio tempo e denaro, il costo di informazioni non verificate o inaffidabili diventa impossibile da ignorare.
Questo articolo è stato originariamente pubblicato su Streaming Media.
Note
- I modelli di linguaggio (LLM) sono una tipologia di IA generativa che crea contenuti sulla base di modelli appresi.
- Il grounding è il processo che consiste nel collegare un modello di linguaggio di grandi dimensioni (LLM) alle informazioni del mondo reale per migliorare l'affidabilità e la pertinenza delle sue risposte.
- Il tempo totale dedicato alla TV è rimasto stabile a 33-35 ore alla settimana negli ultimi anni; dati Nielsen Insights (Nielsen , Nielsen Impact)
Perché i modelli linguistici di grandi dimensioni non basati su dati non possono risolvere il problema della scoperta dei contenuti
I modelli di linguaggio di grandi dimensioni (LLM) hanno il potere di alleviare le crescenti frustrazioni legate alla ricerca di contenuti, ma non se forniscono risultati scadenti.
Incoerenze nella trama nell'IA
Senza una solida base, i modelli linguistici di grandi dimensioni non sono in grado di fornire risultati di ricerca e scoperta accurati agli spettatori televisivi.
I contenuti sportivi sui servizi SVOD globali rivaleggeranno presto con i cataloghi cinematografici
L'offerta sportiva dei fornitori globali di servizi SVOD supera ormai i 38.500 programmi.