
By Tyler Bell, SVP Product
As companies embrace generative AI systems such as large language models (LLMs1) for the efficiencies they can deliver, an array of legacy technologies will become increasingly obsolete. In TV, LLMs will augment–and eventually replace–traditional databases and rudimentary search functions. Over time, they will become the default engines for delivering next-generation entertainment experiences.
This shift will be transformational for consumers. TV audiences, for example, will no longer be limited to basic search queries when they are looking for something to watch.
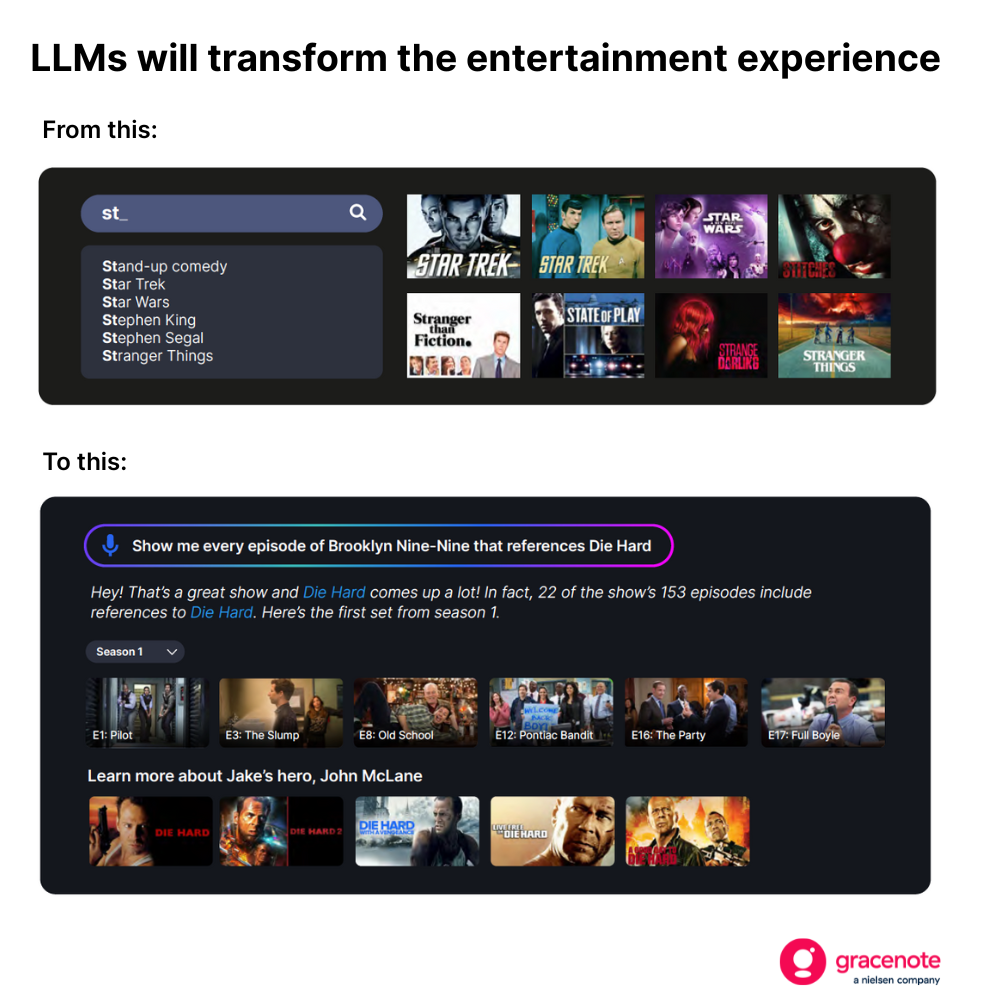
But building this type of experience—one that returns current, accurate and relevant results—requires more than just a well-trained LLM.
That’s because LLMs are not comprehensive knowledge banks. They are predictive engines that generate responses based on patterns learned from their training data. And all too often, that data is flawed.
A 2022 study conducted by researchers at the University of Southern California found that up to 38% of the common-sense “factual” data used in two separate AI databases was biased. In other words, more than one-third of the foundational data in those systems was inaccurate from the outset.

LLMs also struggle with relatively simple tasks. In March 2025, a Columbia Journalism Review study found that eight generative AI tools produced a collective error rate of 60% when asked to connect a news article excerpt with its corresponding headline, original publisher, publication date and URL. By comparison, a traditional Google search returned the sources within the first three results.
The shortcomings of LLMs are widely understood, and a range of techniques exists to reduce hallucinations and improve contextual relevance. Few would argue against the value of grounding2. However, connecting an LLM to inaccurate data for grounding is just as problematic as using flawed data to train one.
The headline here is that bad data is a real threat. LLMs are powerful tools, but they are only as good as the information they can access.
LLM adoption in CTV
The shift to LLMs is unlikely to happen in a single seismic movement. Instead, it will occur “gradually, then suddenly,” as Hemingway’s Mike Campbell describes his bankruptcy in “The Sun Also Rises.”
LLMs are still a relatively new technology. They have limitations, latency considerations and cost implications that organizations must understand before implementing them within consumer-facing search interfaces. The fundamental challenge, however, is data.
Most CTV interfaces are built on data lakes containing heterogeneous metadata from multiple sources, which must be harmonized and normalized before being indexed and optimized for search. This process requires downloading large datasets in advance, running them through complex ingestion pipelines, and continuously updating them to keep the data current.
LLMs, by contrast, excel at interpreting and reconciling data from multiple sources at runtime, potentially lessening–or even eliminating–the need for traditional data lakes and their associated infrastructure.
At the same time, LLMs bring novel capabilities and huge potential to CTV that would be otherwise impossible with current technology. For example, LLMs can dynamically rewrite or augment a movie or episode description to make it more relevant for individual users.
After a viewer watches The Shawshank Redemption, for instance, an LLM could recommend The Green Mile with a tailored description: “It’s a Stephen King adaptation about hope, set in a prison, with emotional depth similar to The Shawshank Redemption, which you enjoyed previously.”
This kind of contextual recommendation represents a significant improvement over the generic “Because You Watched” prompts. LLMs can apply this approach across all titles in a catalog.
In the near term, LLMs will likely be introduced as complements to existing tech, handling complex or conversational queries that traditional systems cannot. Over time, some organizations will replace their legacy infrastructures entirely. Eventually, LLMs will tip the scales.
Fragmentation has complicated the TV viewing experience
Despite the abundance of available programming, video distribution fragmentation has made discovery harder, not easier, working against content providers.
In fact, a recent industry survey found that nearly 50% of U.S. TV viewers would consider canceling a streaming service because they cannot find something to watch. Among audiences aged 25 to 34, that figure rises to 58%.

More content does not necessarily translate into more viewing time3. In practice, overwhelming choice can lead viewers to abandon their searches altogether and decide to do something else.
This is where LLMs can help—but only when they are grounded in the right data.
For CTV platforms, reliable, industry-standard entertainment data is an ideal grounding source. In addition to providing standardized program information, it includes up-to-date TV listings, which are essential for audiences who know what they want to watch but not where to find it. This is especially critical for live sports.

Over time, LLMs will enable transformational TV experiences for viewers. Looking for the top horror movies of 1985 by box office revenue? No problem. Want recommendations for the best soccer movies based on critical reviews after watching the World Cup? Easy. Trying to figure out which service is carrying a particular game, show or movie? Covered.
Consumer expectations for how they interact with technology continue to rise, and CTV platforms have an opportunity to get ahead of the curve. LLMs can deliver on that promise–but only when anchored in trusted, up-to-date data. With TV viewers constantly reevaluating where they spend their time and money, the cost of unvetted or unreliable information becomes impossible to ignore.
This article originally appeared on Streaming Media.
Notes
- LLMs are types of generative AI that create content based on learned patterns.
- Grounding is the process of connecting an LLM to real-world information to improve the trustworthiness and relevance of its responses.
- Total time spent with TV has remained flat at 33-35 hours per week over the past few years; Nielsen Audience Insights Data (Nielsen NPOWER, Nielsen Media Impact)
Can AI find the right TV episode? Not reliably.
Without proper grounding, LLM responses about TV episodes will usually be incorrect.
Why ungrounded large language models can’t fix content discovery
LLMs have the power to alleviate growing frustrations about content discovery—but not if they deliver bad results.
Plot holes in AI
Without proper grounding, large language models aren’t able to deliver accurate search and discovery results for TV viewers.