
Door Tyler Bell, SVP Product
Naarmate bedrijven generatieve AI-systemen zoals grote taalmodellen (LLM’s1) gaan gebruiken vanwege de efficiëntie die deze kunnen opleveren, zal een reeks verouderde technologieën steeds meer achterhaald raken. In de televisiesector zullen LLM’s traditionele databases en rudimentaire zoekfuncties aanvullen – en uiteindelijk vervangen. Na verloop van tijd zullen ze de standaardmotoren worden voor het bieden van entertainmentervaringen van de volgende generatie.
Deze verandering zal voor consumenten een ware ommekeer betekenen. Tv-kijkers zullen bijvoorbeeld niet langer beperkt zijn tot eenvoudige zoekopdrachten wanneer ze op zoek zijn naar iets om te kijken.
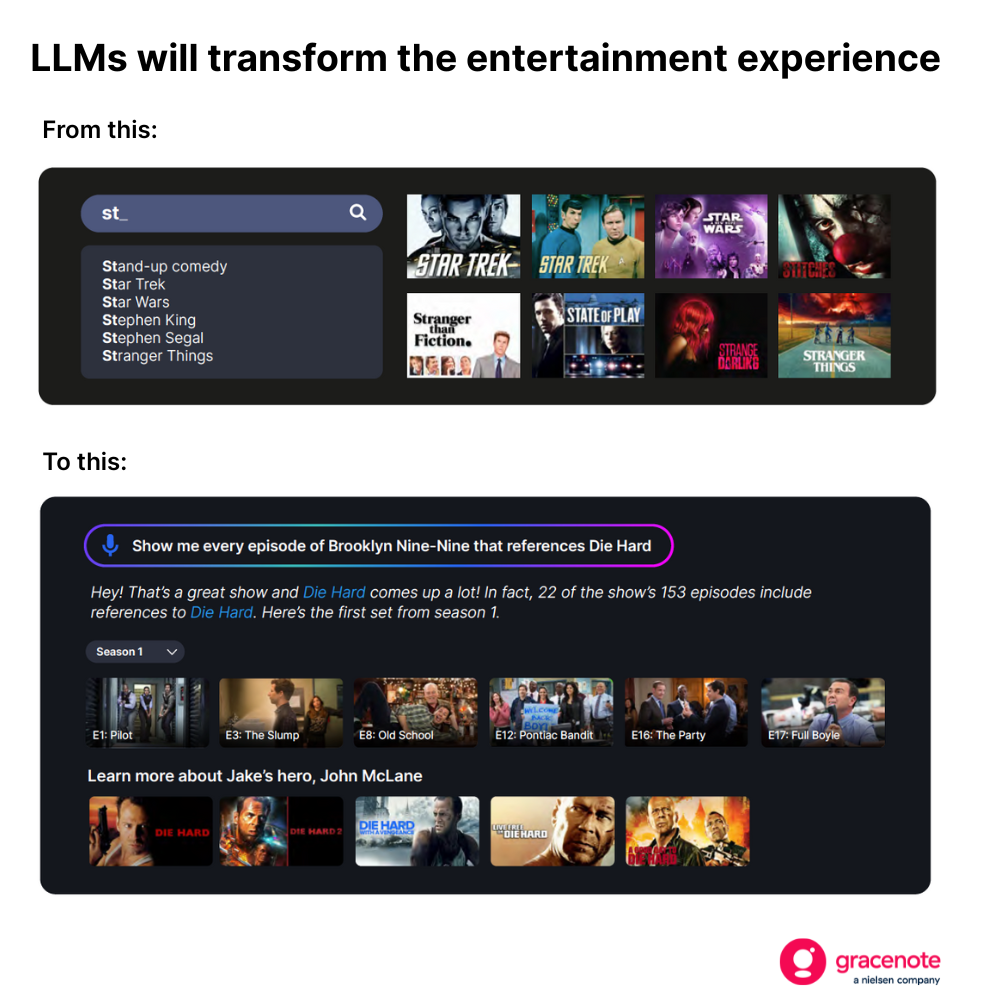
Maar om een dergelijke ervaring te creëren – een ervaring die actuele, nauwkeurige en relevante resultaten oplevert – is meer nodig dan alleen een goed getraind LLM.
Dat komt omdat LLM’s geen alomvattende kennisbanken zijn. Het zijn voorspellende systemen die antwoorden genereren op basis van patronen die ze uit hun trainingsgegevens hebben geleerd. En maar al te vaak zijn die gegevens onjuist.
Uit een onderzoek uit 2022, uitgevoerd door onderzoekers van de University of Southern California, bleek dat tot 38% van de zogenaamd ‘feitelijke’ gegevens die in twee afzonderlijke AI-databases werden gebruikt, vertekend was. Met andere woorden: meer dan een derde van de basisgegevens in die systemen was vanaf het begin onjuist.

LLM’s hebben ook moeite met relatief eenvoudige taken. In maart 2025 bleek uit een onderzoek van de Columbia Journalism Review dat acht generatieve AI-tools een gezamenlijk foutenpercentage van 60% hadden toen ze werden gevraagd een fragment uit een nieuwsartikel te koppelen aan de bijbehorende kop, de oorspronkelijke uitgever, de publicatiedatum en de URL. Ter vergelijking: bij een traditionele Google-zoekopdracht werden de bronnen al in de eerste drie resultaten weergegeven.
De tekortkomingen van grote taalmodellen (LLM’s) zijn algemeen bekend, en er bestaan diverse technieken om hallucinaties te verminderen en de contextuele relevantie te verbeteren. Weinigen zullen de waarde van‘grounding’2 betwisten. Het koppelen van een LLM aan onnauwkeurige gegevens voor grounding is echter net zo problematisch als het gebruik van gebrekkige gegevens om een dergelijk model te trainen.
Het belangrijkste punt hier is dat slechte gegevens een reële bedreiging vormen. Grote taalmodellen zijn krachtige hulpmiddelen, maar ze zijn slechts zo goed als de informatie waartoe ze toegang hebben.
De invoering van LLM in CTV
De overgang naar LLM’s zal waarschijnlijk niet in één grote omwenteling plaatsvinden. In plaats daarvan zal deze zich „geleidelijk, en dan plotseling“ voltrekken, zoals Mike Campbell van Hemingway zijn faillissement beschrijft in „The Sun Also Rises“.
Grote taalmodellen (LLM’s) zijn nog steeds een relatief nieuwe technologie. Ze hebben beperkingen, vereisen aandacht voor latentie en brengen kosten met zich mee, zaken die organisaties moeten begrijpen voordat ze deze modellen implementeren in zoekinterfaces voor consumenten. De grootste uitdaging is echter de data.
De meeste CTV-interfaces zijn gebaseerd op datameren die heterogene metadata uit verschillende bronnen bevatten. Deze gegevens moeten worden geharmoniseerd en genormaliseerd voordat ze kunnen worden geïndexeerd en geoptimaliseerd voor zoekopdrachten. Dit proces vereist dat er vooraf grote datasets worden gedownload, dat deze door complexe opnamepijplijnen worden geleid en dat ze voortdurend worden bijgewerkt om de gegevens actueel te houden.
Grote taalmodellen (LLM’s) blinken daarentegen uit in het interpreteren en samenvoegen van gegevens uit meerdere bronnen tijdens de uitvoering, waardoor de behoefte aan traditionele datameren en de bijbehorende infrastructuur mogelijk wordt verminderd – of zelfs volledig verdwijnt.
Tegelijkertijd bieden LLM’s nieuwe mogelijkheden en een enorm potentieel voor CTV, die met de huidige technologie onmogelijk zouden zijn. Zo kunnen LLM’s bijvoorbeeld de beschrijving van een film of aflevering dynamisch herschrijven of aanvullen, zodat deze beter aansluit bij de individuele gebruiker.
Als een kijker bijvoorbeeld *The Shawshank Redemption* heeft gezien, zou een LLM *The Green Mile* kunnen aanbevelen met een op maat gemaakte beschrijving: „Het is een verfilming van een verhaal van Stephen King over hoop, die zich afspeelt in een gevangenis, met een emotionele diepgang die vergelijkbaar is met die van *The Shawshank Redemption*, die je eerder met plezier hebt bekeken.”
Dit soort contextgebaseerde aanbevelingen vormen een aanzienlijke verbetering ten opzichte van de algemene suggesties van het type „Omdat je dit hebt bekeken“. Grote taalmodellen kunnen deze aanpak toepassen op alle titels in een catalogus.
Op korte termijn zullen LLM’s waarschijnlijk worden ingezet als aanvulling op bestaande technologie, om complexe of conversatiegerichte vragen te verwerken die traditionele systemen niet aankunnen. Na verloop van tijd zullen sommige organisaties hun verouderde infrastructuur volledig vervangen. Uiteindelijk zullen LLM’s de doorslag geven.
De versnippering heeft het tv-kijken bemoeilijkt
Ondanks het enorme aanbod aan programma’s heeft de versnippering van de videodistributie het vinden van content juist moeilijker gemaakt in plaats van gemakkelijker, wat in het nadeel werkt van content .
Uit een recent onderzoek in de sector blijkt zelfs dat bijna 50% van de Amerikaanse tv-kijkers zou overwegen een streamingdienst op te zeggen omdat ze niets kunnen vinden om naar te kijken. Bij kijkers in de leeftijdscategorie van 25 tot 34 jaar loopt dat percentage op tot 58%.

Meer content niet per se dater langerwordt gekeken³. In de praktijk kan een overweldigend aanbod ertoe leiden dat kijkers hun zoektocht helemaal opgeven en besluiten iets anders te gaan doen.
Dit is waar LLM’s van pas kunnen komen – maar alleen als ze op de juiste gegevens zijn gebaseerd.
Voor CTV-platforms vormen betrouwbare entertainmentgegevens volgens de branche-standaard een ideale basis. Naast gestandaardiseerde programma-informatie bevatten deze ook actuele tv-programma-overzichten, die onmisbaar zijn voor kijkers die wel weten wat ze willen zien, maar niet waar ze dat kunnen vinden. Dit is met name van cruciaal belang voor live sportuitzendingen.

Op termijn zullen grote taalmodellen kijkers baanbrekende tv-ervaringen bieden. Op zoek naar de populairste horrorfilms van 1985 op basis van de opbrengsten? Geen probleem. Wil je na het kijken naar het WK voetbal aanbevelingen voor de beste voetbalfilms op basis van recensies? Makkelijk. Probeer je uit te zoeken welke dienst een bepaalde wedstrijd, serie of film uitzendt? Dat regelen we.
De verwachtingen van consumenten ten aanzien van hun interactie met technologie blijven stijgen, en CTV-platforms hebben de kans om voorop te lopen. Grote taalmodellen (LLM’s) kunnen die belofte waarmaken – maar alleen als ze zijn gebaseerd op betrouwbare, actuele gegevens. Nu tv-kijkers voortdurend heroverwegen waar ze hun tijd en geld aan besteden, kunnen de kosten van ongecontroleerde of onbetrouwbare informatie niet langer worden genegeerd.
Dit artikel verscheen oorspronkelijk op Streaming Media.
Aantekeningen
- LLM’s zijn vormen van generatieve AI die content genereren content van aangeleerde patronen.
- Grounding is het proces waarbij een LLM wordt gekoppeld aan informatie uit de echte wereld om de betrouwbaarheid en relevantie van zijn antwoorden te verbeteren.
- De totale tijd die aan tv wordt besteed, is de afgelopen jaren stabiel gebleven op 33-35 uur per week; gegevens Nielsen Insights (Nielsen , Nielsen Impact)
Waarom grote taalmodellen zonder grondgegevens het probleem van content niet kunnen oplossen
Grote taalmodellen (LLM’s) kunnen de toenemende frustraties over content verlichten – maar niet als ze slechte resultaten opleveren.
Gaten in het verhaal van AI
Zonder een degelijke basis kunnen grote taalmodellen geen nauwkeurige zoek- en ontdekkingsresultaten leveren voor tv-kijkers.
content wereldwijde SVOD-diensten zal binnenkort concurreren met filmcatalogi
Het aanbod aan sportprogramma’s bij wereldwijde SVOD-aanbieders bedraagt inmiddels meer dan 38.500 programma’s.