
タイラー・ベル、製品担当上級副社長
企業が効率化を図るために大規模言語モデル(LLM1)などの生成AIシステムを導入するにつれ、従来の技術の多くは次第に時代遅れになっていくでしょう。テレビ業界においても、LLMは従来のデータベースや初歩的な検索機能を補完し、最終的にはそれらに取って代わるでしょう。やがて、LLMは次世代のエンターテインメント体験を提供する標準的なエンジンとなるでしょう。
この変化は、消費者にとって画期的なものとなるでしょう。例えば、テレビ視聴者は、見たい番組を探す際に、もはや基本的な検索クエリだけに頼る必要がなくなるでしょう。
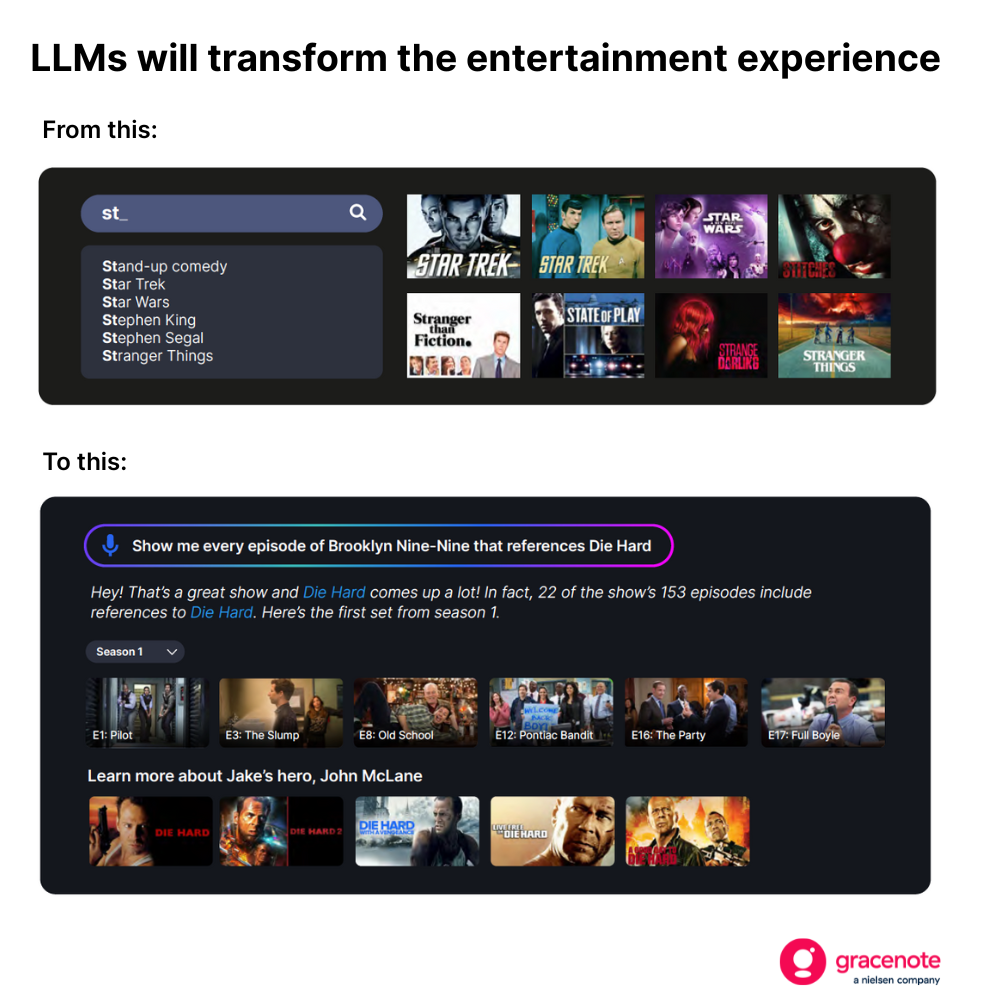
しかし、最新かつ正確で関連性の高い検索結果を返すような体験を構築するには、単に高度に訓練されたLLMだけでは不十分です。
なぜなら、LLMは包括的な知識の宝庫ではないからです。LLMは、学習データから学んだパターンに基づいて応答を生成する予測エンジンに過ぎません。そして、そのデータには欠陥があることがあまりにも多いのです。
南カリフォルニア大学の研究者らが2022年に実施した調査によると、2つの異なるAIデータベースで使用されている「常識的な」事実データの最大38%に偏りが見られた。つまり、これらのシステムの基礎データの3分の1以上が、そもそも不正確だったということだ。

LLMは、比較的単純なタスクでも苦戦している。2025年3月、コロンビア・ジャーナリズム・レビューの調査によると、ニュース記事の抜粋と、それに対応する見出し、元の出版社、掲載日、URLを結びつけるよう求められた際、8つの生成AIツールの総合的な誤答率は60%に達した。これに対し、従来のGoogle検索では、最初の3件の結果の中に情報源が表示された。
LLMの欠点は広く認識されており、幻覚現象を軽減し、文脈との関連性を高めるための様々な手法が存在する。「グラウンディング」2の有用性を否定する人はほとんどいないだろう。しかし、グラウンディングのためにLLMを不正確なデータと結びつけることは、欠陥のあるデータを使ってLLMを訓練することと同様に問題がある。
ここで重要なのは、質の悪いデータが真の脅威であるということです。LLMは強力なツールですが、その性能はアクセスできる情報の質に左右されます。
CTVにおけるLLMの導入
LLMへの移行は、一挙に起こるような劇的な変化とはならないだろう。むしろ、ヘミングウェイの『太陽もまた昇る』でマイク・キャンベルが自身の破産について語ったように、「徐々に、そして突然」起こるものとなるだろう。
LLMはまだ比較的新しい技術です。組織が消費者向けの検索インターフェースに導入する前に、その限界や遅延の問題、コスト面での影響を理解しておく必要があります。しかし、根本的な課題はデータにあります。
ほとんどのCTVインターフェースは、複数のソースから集められた異種混合のメタデータを含むデータレイクを基盤として構築されています。これらのデータは、インデックス化や検索最適化を行う前に、整合と正規化を行う必要があります。このプロセスでは、事前に大規模なデータセットをダウンロードし、複雑な取り込みパイプラインを通過させ、データを最新の状態に保つために継続的に更新する必要があります。
対照的に、LLMは実行時に複数のソースからのデータを解釈・統合することに優れており、従来のデータレイクやそれに関連するインフラの必要性を軽減し、場合によっては不要にする可能性さえある。
同時に、LLMはCTVに、現行の技術では実現不可能な新たな機能と大きな可能性をもたらします。例えば、LLMは映画やエピソードの説明文を動的に書き換えたり補足したりすることで、個々のユーザーにとってより関連性の高い内容にすることができます。
例えば、視聴者が『ショーシャンクの空に』を観た後、LLMは『グリーン・マイル』を次のようなパーソナライズされた説明付きで推薦することができます。「これはスティーヴン・キング原作の映画で、刑務所を舞台にした『希望』をテーマにした作品です。以前お楽しみいただいた『ショーシャンクの空に』と同様、心に響く深みがあります。」
このような文脈に応じたレコメンデーションは、一般的な「あなたが視聴した作品に基づいて」という提案に比べて大幅な改善となります。LLMはこのアプローチをカタログ内のすべてのタイトルに適用することができます。
当面は、LLMが既存の技術を補完する形で導入され、従来のシステムでは対応できない複雑な問い合わせや会話形式の問い合わせを処理することになるでしょう。やがて、一部の組織では従来のインフラを完全に置き換えるようになるでしょう。最終的には、LLMが決定的な役割を果たすことになるでしょう。
コンテンツの断片化により、テレビ視聴体験は複雑化している
利用可能な番組は豊富にあるにもかかわらず、動画配信の分散化により、コンテンツの発見は容易になるどころか、かえって困難になっており、コンテンツプロバイダーにとって不利な状況となっている。
実際、最近の業界調査によると、米国のテレビ視聴者の50%近くが、「見たい番組が見つからない」という理由でストリーミングサービスの解約を検討していることが明らかになった。25歳から34歳の視聴者に限れば、その割合は58%にまで上昇する。

コンテンツの量が増えたからといって、必ずしも視聴時間が延びるわけではない³。実際には、選択肢が多すぎると、視聴者は検索を諦めて、別のことをするようになってしまうことがある。
ここでLLMが役立つのですが、それは適切なデータに基づいて構築されている場合に限ります。
CTVプラットフォームにとって、信頼性の高い業界標準のエンターテインメントデータは、理想的な基盤となります。標準化された番組情報を提供するだけでなく、最新のテレビ番組表も含まれており、これは「何を見たいかは分かっているが、どこで見られるか分からない」という視聴者にとって不可欠な情報です。これは特にスポーツの生中継において極めて重要です。

将来的には、LLM(大規模言語モデル)が視聴者に画期的なテレビ体験をもたらすことになるでしょう。1985年の興行収入ランキング上位のホラー映画を探していますか?問題ありません。ワールドカップを観戦した後、批評家の評価に基づいたおすすめのサッカー映画を知りたいですか?簡単です。特定の試合や番組、映画をどの配信サービスで視聴できるか知りたいですか?お任せください。
テクノロジーとの関わり方に対する消費者の期待は高まり続けており、CTVプラットフォームにはその潮流を先取りするチャンスがあります。LLM(大規模言語モデル)はその期待に応えることができますが、それは信頼性が高く最新のデータに基づいている場合に限られます。テレビ視聴者が時間とお金をどこに費やすかを絶えず見直している今、検証されていない情報や信頼性の低い情報の代償は、もはや無視できないものとなっています。
この記事は、もともと『Streaming Media』に掲載されたものです。
備考
- LLMは、学習したパターンに基づいてコンテンツを生成する生成AIの一種です。
- グラウンディングとは、LLMを現実世界の情報と結びつけることで、その応答の信頼性と関連性を高めるプロセスです。
- ここ数年、テレビ視聴時間は週あたり33~35時間で横ばいとなっている。Nielsen (Nielsen 、Nielsen )
なぜ、実世界との接点を持たない大規模言語モデルではコンテンツ発見の問題を解決できないのか
LLMには、コンテンツ発見に関する高まりつつある不満を和らげる力がある――ただし、質の低い結果しか出せないようでは意味がない。
世界各国のSVODサービスにおけるスポーツコンテンツは、まもなく映画のラインナップに匹敵する規模になるだろう
世界のSVODプロバイダーにおけるスポーツ番組の配信数は、現在3万8500本を超えている。