
Par Tyler Bell, vice-président directeur Produits
À mesure que les entreprises adoptent des systèmes d'IA générative, tels que les grands modèles linguistiques (LLM¹), pour les gains d'efficacité qu'ils permettent d'obtenir, toute une série de technologies existantes deviendront de plus en plus obsolètes. Dans le domaine de la télévision, les LLM viendront compléter – puis finiront par remplacer – les bases de données traditionnelles et les fonctions de recherche rudimentaires. Au fil du temps, ils deviendront les moteurs par défaut pour offrir des expériences de divertissement de nouvelle génération.
Ce changement va révolutionner la vie des consommateurs. Les téléspectateurs, par exemple, ne se limiteront plus à de simples requêtes de recherche lorsqu'ils chercheront quelque chose à regarder.
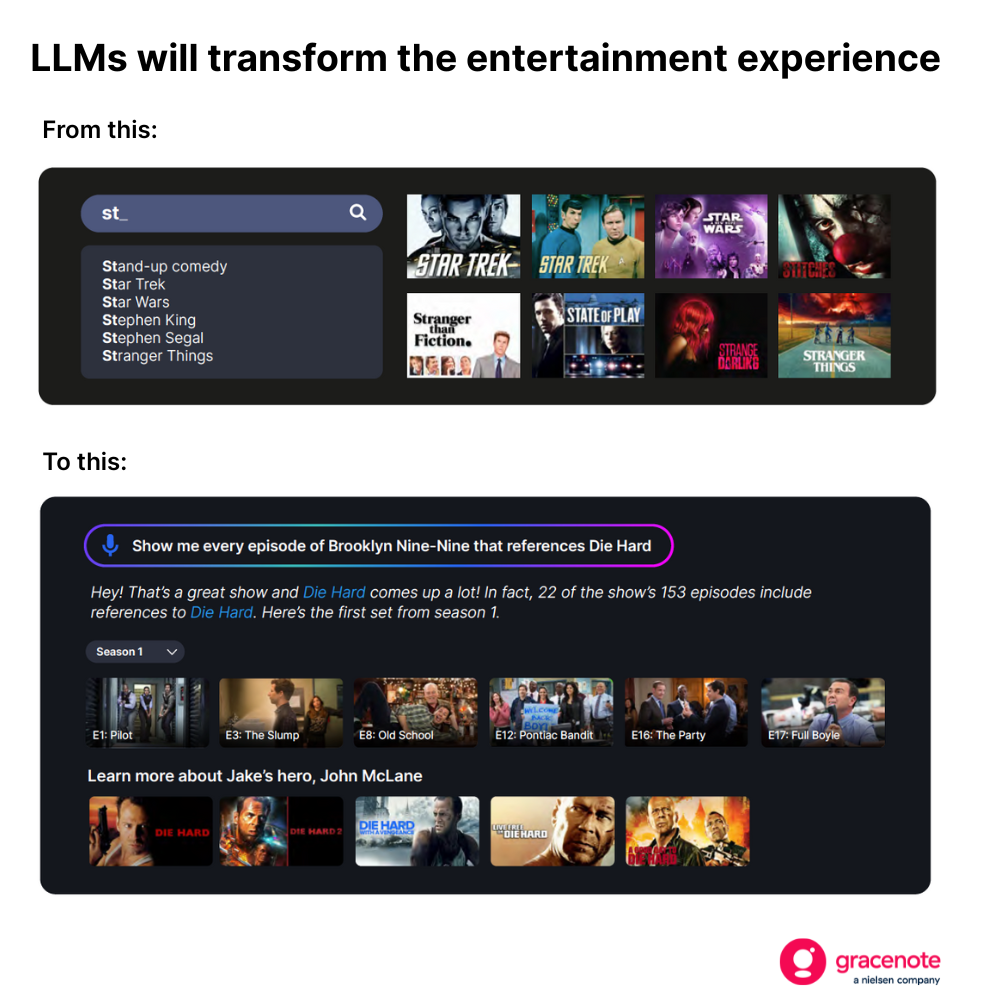
Mais pour mettre en place ce type d'expérience — qui fournit des résultats à jour, précis et pertinents —, il ne suffit pas d'un modèle de langage de grande capacité (LLM) bien entraîné.
En effet, les grands modèles de langage ne sont pas des bases de connaissances exhaustives. Ce sont des moteurs prédictifs qui génèrent des réponses en s'appuyant sur des schémas appris à partir de leurs données d'entraînement. Et bien trop souvent, ces données sont erronées.
Une étude réalisée en 2022 par des chercheurs de l'Université de Californie du Sud a révélé que jusqu'à 38 % des données « factuelles » de bon sens utilisées dans deux bases de données distinctes dédiées à l'IA étaient biaisées. En d'autres termes, plus d'un tiers des données de base de ces systèmes étaient inexactes dès le départ.

Les grands modèles de langage (LLM) peinent également à accomplir des tâches relativement simples. En mars 2025, une étude de la Columbia Journalism Review a révélé que huit outils d’IA générative affichaient un taux d’erreur cumulé de 60 % lorsqu’on leur demandait de relier un extrait d’article de presse à son titre, à son éditeur d’origine, à sa date de publication et à son URL. À titre de comparaison, une recherche Google classique affichait les sources dès les trois premiers résultats.
Les limites des grands modèles de langage (LLM) sont largement reconnues, et il existe toute une série de techniques permettant de réduire les « hallucinations » et d'améliorer la pertinence contextuelle. Rares sont ceux qui contesteraient l'intérêt del'ancrage2. Cependant, relier un grand modèle de langage à des données inexactes à des fins d'ancrage est tout aussi problématique que d'utiliser des données erronées pour l'entraîner.
En résumé, les données de mauvaise qualité constituent une menace réelle. Les modèles de langage génératifs (LLM) sont des outils puissants, mais leur efficacité dépend entièrement de la qualité des informations auxquelles ils ont accès.
L'adoption du LLM dans le domaine de la télévision connectée
Le passage aux grands modèles de langage (LLM) ne devrait pas se faire d'un seul coup. Il se produira plutôt « progressivement, puis soudainement », comme le décrit Mike Campbell, personnage d'Hemingway, à propos de sa faillite dans *Le soleil se lève aussi*.
Les grands modèles de langage (LLM) constituent encore une technologie relativement récente. Ils présentent des limites, des contraintes de latence et des implications financières que les entreprises doivent bien comprendre avant de les mettre en œuvre dans des interfaces de recherche destinées au grand public. Le principal défi réside toutefois dans les données.
La plupart des interfaces CTV s'appuient sur des lacs de données contenant des métadonnées hétérogènes provenant de multiples sources, qui doivent être harmonisées et normalisées avant d'être indexées et optimisées pour la recherche. Ce processus nécessite de télécharger au préalable de volumineux ensembles de données, de les traiter via des pipelines d'ingestion complexes et de les mettre à jour en permanence afin de garantir l'actualité des données.
Les grands modèles de langage (LLM), en revanche, excellent dans l'interprétation et la mise en cohérence de données provenant de multiples sources en temps réel, ce qui pourrait réduire, voire éliminer, le recours aux lacs de données traditionnels et à l'infrastructure qui y est associée.
Parallèlement, les grands modèles de langage (LLM) apportent à la télévision connectée (CTV) des fonctionnalités inédites et un immense potentiel qui seraient impossibles à réaliser avec les technologies actuelles. Par exemple, les LLM peuvent réécrire ou enrichir de manière dynamique la description d'un film ou d'un épisode afin de la rendre plus pertinente pour chaque utilisateur.
Par exemple, après qu’un spectateur a regardé « Les Évadés », un modèle LLM pourrait lui recommander « La Ligne verte » avec une description personnalisée : « Il s’agit d’une adaptation d’un roman de Stephen King qui traite de l’espoir, dont l’action se déroule en prison, et qui présente une profondeur émotionnelle similaire à celle des « Évadés », que vous avez appréciés précédemment. »
Ce type de recommandation contextuelle constitue une amélioration notable par rapport aux suggestions génériques du type « Vous avez regardé… ». Les modèles de langage de grande envergure (LLM) peuvent appliquer cette approche à l'ensemble des titres d'un catalogue.
À court terme, les grands modèles de langage (LLM) seront probablement déployés en complément des technologies existantes, pour traiter les requêtes complexes ou conversationnelles que les systèmes traditionnels ne sont pas en mesure de gérer. À terme, certaines organisations remplaceront entièrement leurs infrastructures existantes. À terme, les grands modèles de langage feront pencher la balance.
La fragmentation a compliqué l'expérience télévisuelle
Malgré l'abondance de programmes disponibles, la fragmentation de la distribution vidéo a rendu la découverte des contenus plus difficile, et non plus facile, ce qui va à l'encontre des intérêts des fournisseurs de contenu.
En effet, une récente enquête menée auprès des professionnels du secteur a révélé que près de 50 % des téléspectateurs américains envisageraient de résilier leur abonnement à un streaming parce qu'ils ne trouvent rien à regarder. Chez les 25-34 ans, ce chiffre atteint 58 %.

Une offre plus riche ne se traduit pas nécessairement par une augmentationdu temps passé à regarder3. Dans la pratique, un choix trop vaste peut inciter les spectateurs à abandonner complètement leurs recherches et à se tourner vers autre chose.
C'est là que les grands modèles de langage peuvent être utiles, mais seulement s'ils s'appuient sur les bonnes données.
Pour les plateformes de télévision par câble, des données fiables sur les programmes de divertissement, conformes aux normes du secteur, constituent une base de référence idéale. Outre des informations standardisées sur les programmes, elles comprennent des grilles de programmes actualisées, indispensables pour les téléspectateurs qui savent ce qu’ils veulent regarder mais ne savent pas où le trouver. Cela est particulièrement crucial pour les événements sportifs en direct.

À terme, les grands modèles linguistiques (LLM) offriront aux téléspectateurs des expériences télévisuelles révolutionnaires. Vous cherchez les meilleurs films d'horreur de 1985 en termes de recettes au box-office ? Pas de problème. Vous voulez des recommandations sur les meilleurs films de football d'après les critiques après avoir regardé la Coupe du monde ? C'est facile. Vous essayez de savoir sur quelle plateforme est diffusé un match, une émission ou un film en particulier ? On s'en occupe.
Les attentes des consommateurs quant à leur interaction avec la technologie ne cessent de croître, et les plateformes de télévision connectée (CTV) ont là l'occasion de prendre une longueur d'avance. Les modèles de langage génératifs (LLM) peuvent tenir cette promesse, mais seulement s'ils s'appuient sur des données fiables et à jour. Alors que les téléspectateurs réévaluent sans cesse la manière dont ils dépensent leur temps et leur argent, le coût d'informations non vérifiées ou peu fiables devient impossible à ignorer.
Cet article a été initialement publié sur Streaming Media.
Notes
- Les grands modèles de langage (LLM) sont des types d'IA générative qui créent du contenu à partir de modèles appris.
- L'ancrage consiste à relier un modèle de langage de grande capacité (LLM) à des informations du monde réel afin d'améliorer la fiabilité et la pertinence de ses réponses.
- Le temps total passé devant la télévision est resté stable ces dernières années, oscillant entre 33 et 35 heures par semaine ; données Nielsen Insights (Nielsen , Nielsen Impact)
Pourquoi les grands modèles linguistiques non ancrés ne peuvent pas résoudre le problème de la découverte de contenu
Les modèles de langage de grande envergure (LLM) ont le pouvoir d'apaiser les frustrations croissantes liées à la recherche de contenu, mais pas s'ils fournissent de mauvais résultats.
Incohérences dans l'IA
Sans une base solide, les grands modèles linguistiques ne sont pas en mesure de fournir des résultats de recherche et de découverte précis aux téléspectateurs.
Les contenus sportifs proposés par les plateformes mondiales de SVOD rivaliseront bientôt avec les catalogues de films
L'offre sportive proposée par les plateformes mondiales de SVOD dépasse désormais les 38 500 programmes.