
Por Tyler Bell, vice-presidente sênior de Produtos
À medida que as empresas adotam sistemas de IA generativa, como os grandes modelos de linguagem (LLMs¹), devido à eficiência que estes proporcionam, uma série de tecnologias antigas tornar-se-á cada vez mais obsoleta. Na televisão, os LLMs irão complementar — e, eventualmente, substituir — as bases de dados tradicionais e as funções de pesquisa rudimentares. Com o tempo, tornar-se-ão os motores padrão para proporcionar experiências de entretenimento de última geração.
Esta mudança será revolucionária para os consumidores. O público televisivo, por exemplo, já não ficará limitado a pesquisas básicas quando procurar algo para ver.
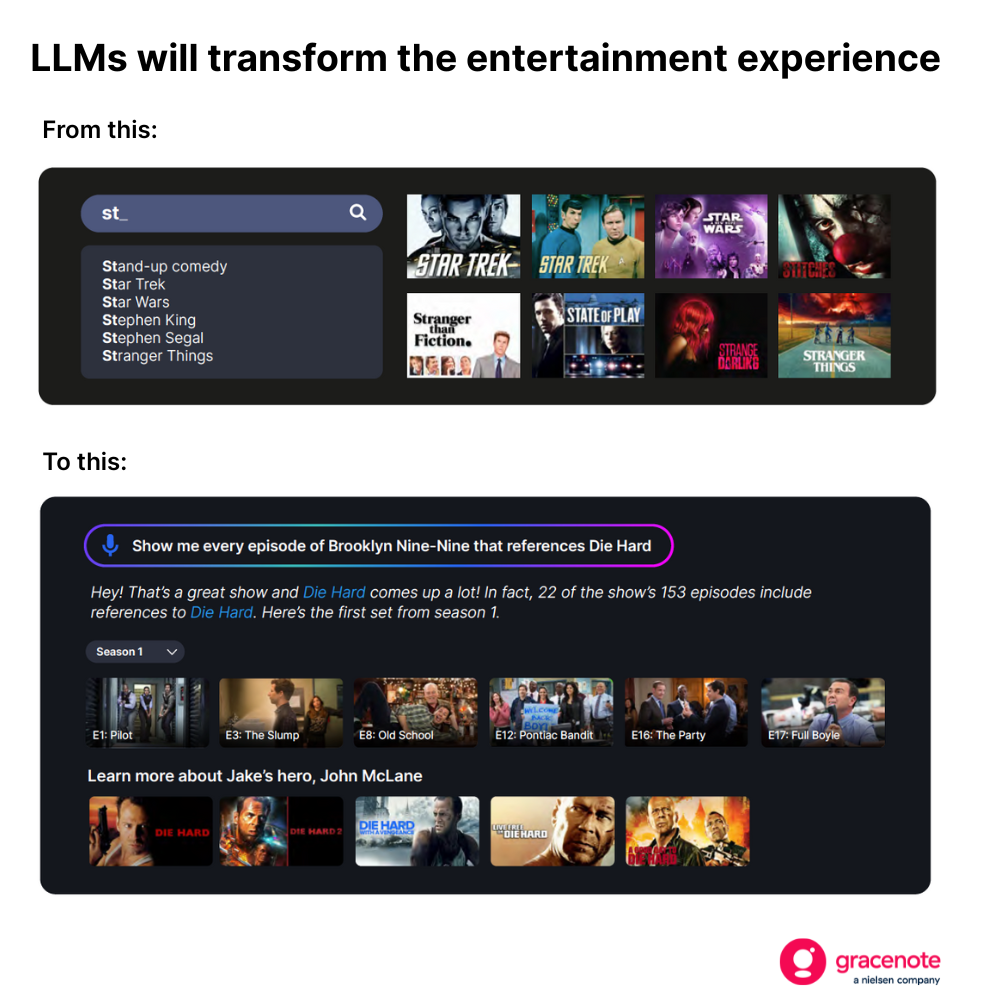
Mas criar este tipo de experiência — que forneça resultados atuais, precisos e relevantes — requer mais do que apenas um LLM bem treinado.
Isso porque os LLMs não são bancos de conhecimento exaustivos. São motores de previsão que geram respostas com base em padrões aprendidos a partir dos seus dados de treino. E, com demasiada frequência, esses dados estão incorretos.
Um estudo realizado em 2022 por investigadores da Universidade do Sul da Califórnia revelou que até 38 % dos dados «factuais» de senso comum utilizados em duas bases de dados de IA distintas eram tendenciosos. Por outras palavras, mais de um terço dos dados fundamentais desses sistemas era impreciso desde o início.

Os LLMs também têm dificuldades com tarefas relativamente simples. Em março de 2025, um estudo da Columbia Journalism Review revelou que oito ferramentas de IA generativa apresentaram uma taxa de erro coletiva de 60% quando solicitadas a associar um excerto de um artigo noticioso ao seu título, editor original, data de publicação e URL correspondentes. Em comparação, uma pesquisa tradicional no Google apresentou as fontes nos três primeiros resultados.
As limitações dos modelos de linguagem de grande escala (LLMs) são amplamente reconhecidas, e existe uma variedade de técnicas para reduzir as alucinações e melhorar a relevância contextual. Poucos contestariam o valor do«grounding»2. No entanto, ligar um LLM a dados imprecisos para o «grounding» é tão problemático quanto utilizar dados errados para o treinar.
A conclusão principal é que os dados de má qualidade representam uma ameaça real. Os modelos de linguagem de grande escala (LLMs) são ferramentas poderosas, mas a sua eficácia depende inteiramente da qualidade da informação a que têm acesso.
A adoção do LLM na CTV
É improvável que a transição para os LLMs ocorra num único movimento radical. Em vez disso, irá ocorrer «gradualmente, e depois de repente», tal como Mike Campbell, a personagem de Hemingway, descreve a sua falência em «O Sol Também Se Levanta».
Os LLMs continuam a ser uma tecnologia relativamente nova. Apresentam limitações, questões relacionadas com a latência e implicações em termos de custos que as organizações devem compreender antes de os implementar em interfaces de pesquisa destinadas ao consumidor. O desafio fundamental, no entanto, reside nos dados.
A maioria das interfaces de CTV assenta em lagos de dados que contêm metadados heterogéneos provenientes de várias fontes, os quais têm de ser harmonizados e normalizados antes de serem indexados e otimizados para pesquisa. Este processo requer o descarregamento prévio de grandes conjuntos de dados, a sua processamento através de fluxos de ingestão complexos e a sua atualização contínua para manter os dados atualizados.
Os LLMs, por outro lado, destacam-se na interpretação e reconciliação de dados provenientes de múltiplas fontes em tempo real, o que pode reduzir — ou mesmo eliminar — a necessidade de lagos de dados tradicionais e da infraestrutura a eles associada.
Ao mesmo tempo, os LLMs trazem novas capacidades e um enorme potencial para a CTV, algo que seria impossível com a tecnologia atual. Por exemplo, os LLMs podem reescrever ou complementar dinamicamente a descrição de um filme ou episódio, de modo a torná-la mais relevante para cada utilizador.
Depois de um espectador ver «A Redenção de Shawshank», por exemplo, um LLM poderia recomendar «A Milha Verde» com uma descrição personalizada: «É uma adaptação de Stephen King sobre a esperança, ambientada numa prisão, com uma profundidade emocional semelhante à de «A Redenção de Shawshank», que lhe agradou anteriormente.»
Este tipo de recomendação contextual representa uma melhoria significativa em relação às sugestões genéricas do tipo «Porque viu». Os modelos de linguagem de grande escala (LLMs) podem aplicar esta abordagem a todos os títulos de um catálogo.
A curto prazo, os LLMs serão provavelmente introduzidos como complementos às tecnologias existentes, lidando com consultas complexas ou conversacionais que os sistemas tradicionais não conseguem processar. Com o tempo, algumas organizações substituirão totalmente as suas infraestruturas antigas. A longo prazo, os LLMs acabarão por fazer a diferença.
A fragmentação tem complicado a experiência de ver televisão
Apesar da abundância de programação disponível, a fragmentação da distribuição de vídeo tornou a descoberta mais difícil, e não mais fácil, prejudicando os fornecedores de conteúdos.
De facto, um inquérito recente ao setor revelou que quase 50% dos telespectadores norte-americanos considerariam cancelar um serviço de streaming por não conseguirem encontrar nada para ver. Entre o público com idades compreendidas entre os 25 e os 34 anos, esse valor sobe para 58%.

Mais conteúdo não se traduz necessariamente em maistempo de visualização³. Na prática, uma oferta excessiva de opções pode levar os espectadores a desistir completamente das suas pesquisas e a decidir fazer outra coisa.
É aqui que os LLMs podem ajudar — mas apenas quando se baseiam nos dados certos.
Para as plataformas de televisão por cabo, os dados de entretenimento fiáveis e em conformidade com os padrões do setor constituem uma base ideal. Além de fornecerem informações padronizadas sobre os programas, incluem grelhas de programação atualizadas, essenciais para os espectadores que sabem o que querem ver, mas não sabem onde encontrá-lo. Isto é especialmente importante no caso dos eventos desportivos em direto.

Com o tempo, os LLMs permitirão experiências televisivas revolucionárias para os telespectadores. Procura os melhores filmes de terror de 1985 por receitas de bilheteira? Não há problema. Quer recomendações dos melhores filmes de futebol com base nas críticas, depois de ver o Mundial? É fácil. Está a tentar descobrir qual o serviço que transmite um determinado jogo, programa ou filme? Nós tratamos disso.
As expectativas dos consumidores em relação à forma como interagem com a tecnologia continuam a aumentar, e as plataformas de CTV têm a oportunidade de se antecipar a esta tendência. Os modelos de linguagem de grande escala (LLMs) podem cumprir essa promessa – mas apenas quando assentes em dados fiáveis e atualizados. Com os telespectadores a reavaliar constantemente onde gastam o seu tempo e dinheiro, o custo da informação não verificada ou pouco fiável torna-se impossível de ignorar.
Este artigo foi publicado originalmente na Streaming Media.
Notas
- Os LLMs são tipos de IA generativa que criam conteúdo com base em padrões aprendidos.
- O «grounding» é o processo de ligar um LLM a informações do mundo real para melhorar a fiabilidade e a relevância das suas respostas.
- O tempo total dedicado à televisão manteve-se estável entre 33 e 35 horas por semana nos últimos anos; Dados Nielsen Insights (Nielsen , Nielsen Impact)
Por que razão os modelos de linguagem de grande dimensão sem base não conseguem resolver a questão da descoberta de conteúdos
Os LLMs têm o poder de aliviar as frustrações crescentes relacionadas com a descoberta de conteúdos — mas não se apresentarem maus resultados.
Falhas no enredo da IA
Sem uma base sólida, os grandes modelos de linguagem não conseguem fornecer resultados precisos de pesquisa e descoberta aos telespectadores.
O conteúdo desportivo nos serviços globais de SVOD irá em breve rivalizar com os catálogos de filmes
A oferta de conteúdos desportivos nos serviços globais de SVOD ultrapassa agora os 38 500 programas.