
Por Tyler Bell, vicepresidente sénior de Producto
A medida que las empresas adopten sistemas de IA generativa, como los grandes modelos de lenguaje (LLM¹), por la eficiencia que ofrecen, una serie de tecnologías heredadas quedarán cada vez más obsoletas. En el ámbito de la televisión, los LLM complementarán —y, con el tiempo, sustituirán— a las bases de datos tradicionales y a las funciones de búsqueda rudimentarias. Con el paso del tiempo, se convertirán en los motores predeterminados para ofrecer experiencias de entretenimiento de última generación.
Este cambio supondrá una transformación para los consumidores. Los espectadores de televisión, por ejemplo, ya no se verán limitados a realizar búsquedas básicas cuando busquen algo que ver.
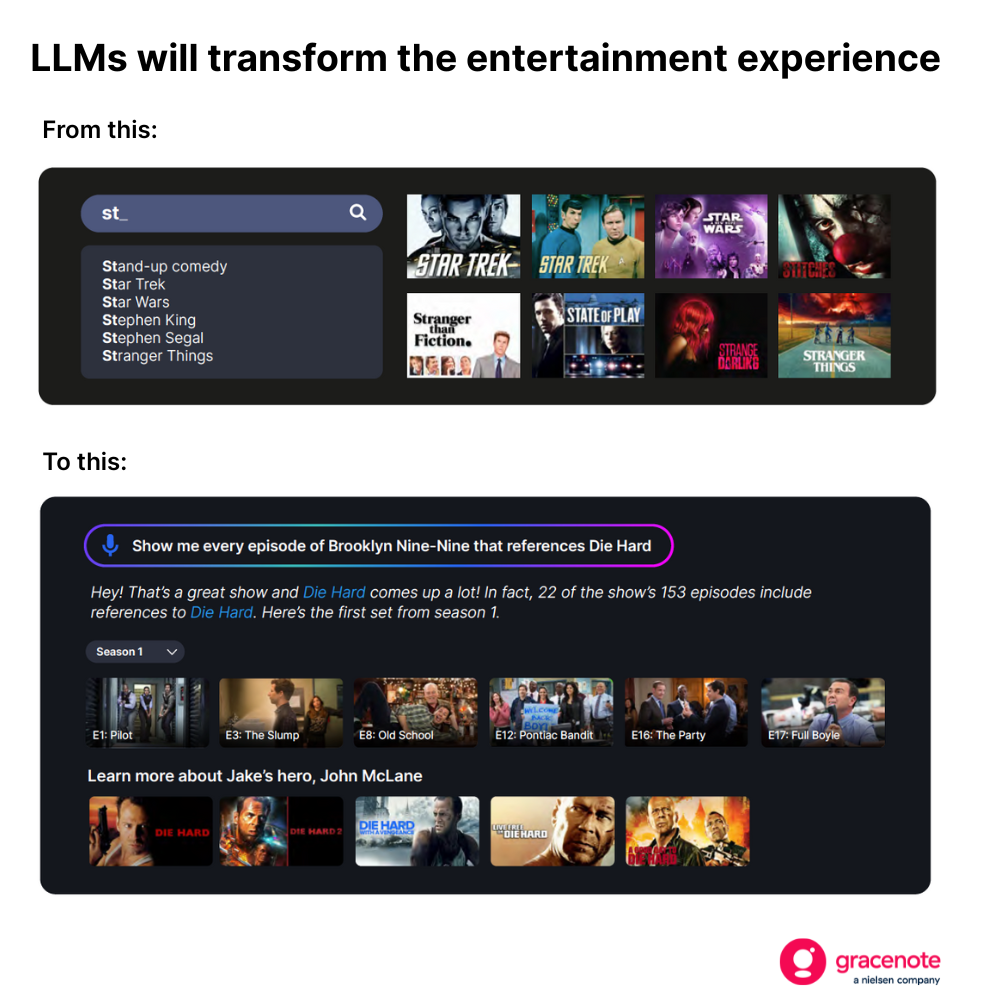
Pero crear este tipo de experiencia —una que ofrezca resultados actuales, precisos y relevantes— requiere algo más que un modelo de lenguaje grande (LLM) bien entrenado.
Esto se debe a que los modelos de lenguaje grande (LLM) no son bases de datos exhaustivas. Son motores predictivos que generan respuestas basadas en patrones aprendidos a partir de sus datos de entrenamiento. Y, con demasiada frecuencia, esos datos son erróneos.
Un estudio realizado en 2022 por investigadores de la Universidad del Sur de California reveló que hasta el 38 % de los datos «objetivos» basados en el sentido común utilizados en dos bases de datos de IA distintas presentaban sesgos. En otras palabras, más de un tercio de los datos fundamentales de esos sistemas eran inexactos desde el principio.

Los modelos de lenguaje grande (LLM) también tienen dificultades con tareas relativamente sencillas. En marzo de 2025, un estudio de la Columbia Journalism Review reveló que ocho herramientas de IA generativa registraron una tasa de error conjunta del 60 % cuando se les pidió que relacionaran un fragmento de un artículo de prensa con su titular correspondiente, el medio de origen, la fecha de publicación y la URL. En comparación, una búsqueda tradicional en Google mostraba las fuentes en los tres primeros resultados.
Las deficiencias de los modelos de lenguaje grande (LLM) son bien conocidas, y existen diversas técnicas para reducir las alucinaciones y mejorar la relevancia contextual. Pocos discutirían el valor del«grounding»2. Sin embargo, conectar un LLM a datos inexactos para el «grounding» es tan problemático como utilizar datos erróneos para entrenarlo.
La conclusión es que los datos erróneos suponen una amenaza real. Los modelos de lenguaje grande (LLM) son herramientas muy potentes, pero su eficacia depende de la calidad de la información a la que tienen acceso.
La adopción de LLM en la televisión conectada
Es poco probable que la transición hacia los modelos de lenguaje grande (LLM) se produzca de un solo golpe. Más bien, tendrá lugar «poco a poco, y luego de repente», tal y como describe Mike Campbell, el personaje de Hemingway, su quiebra en «El sol también sale».
Los modelos de lenguaje grande (LLM) siguen siendo una tecnología relativamente nueva. Presentan limitaciones, cuestiones relacionadas con la latencia y repercusiones económicas que las organizaciones deben comprender antes de implementarlos en interfaces de búsqueda dirigidas al consumidor. Sin embargo, el principal reto son los datos.
La mayoría de las interfaces de CTV se basan en lagos de datos que contienen metadatos heterogéneos procedentes de múltiples fuentes, los cuales deben armonizarse y normalizarse antes de ser indexados y optimizados para la búsqueda. Este proceso requiere descargar previamente grandes conjuntos de datos, procesarlos a través de complejos flujos de ingestión y actualizarlos continuamente para mantener los datos al día.
Los modelos de lenguaje grande (LLM), por el contrario, destacan por su capacidad para interpretar y conciliar datos procedentes de múltiples fuentes en tiempo de ejecución, lo que podría reducir —o incluso eliminar— la necesidad de los lagos de datos tradicionales y su infraestructura asociada.
Al mismo tiempo, los modelos de lenguaje grande (LLM) aportan nuevas capacidades y un enorme potencial a la televisión conectada (CTV) que, de otro modo, serían imposibles con la tecnología actual. Por ejemplo, los LLM pueden reescribir o ampliar dinámicamente la descripción de una película o un episodio para que resulte más relevante para cada usuario.
Por ejemplo, después de que un espectador vea «Cadena perpetua», un modelo de lenguaje grande podría recomendarle «La milla verde » con una descripción personalizada: «Es una adaptación de una obra de Stephen King sobre la esperanza, ambientada en una prisión, con una profundidad emocional similar a la de “Cadena perpetua”, que te gustó tanto».
Este tipo de recomendación contextual supone una mejora significativa con respecto a las sugerencias genéricas del tipo «Porque has visto...». Los modelos de lenguaje grande (LLM) pueden aplicar este enfoque a todos los títulos de un catálogo.
A corto plazo, es probable que los modelos de lenguaje grande (LLM) se introduzcan como complemento de la tecnología existente, encargándose de consultas complejas o conversacionales que los sistemas tradicionales no pueden gestionar. Con el tiempo, algunas organizaciones sustituirán por completo sus infraestructuras heredadas. A la larga, los modelos de lenguaje grande marcarán la diferencia.
La fragmentación ha complicado la experiencia de ver la televisión
A pesar de la gran cantidad de programación disponible, la fragmentación de la distribución de vídeos ha dificultado, en lugar de facilitar, el descubrimiento de contenidos, lo que perjudica a los proveedores de contenidos.
De hecho, una encuesta reciente del sector reveló que casi el 50 % de los telespectadores estadounidenses se plantearía dar de baja un servicio de streaming porque no encuentra nada que ver. Entre el público de entre 25 y 34 años, esa cifra asciende al 58 %.

Una mayor cantidad de contenido no se traduce necesariamente enun mayortiempo de visualización³. En la práctica, una oferta abrumadora puede llevar a los espectadores a abandonar por completo sus búsquedas y decidir hacer otra cosa.
Aquí es donde los modelos de lenguaje grande pueden ser de ayuda, pero solo si se basan en los datos adecuados.
Para las plataformas de televisión en directo, disponer de datos fiables sobre entretenimiento que cumplan los estándares del sector constituye una base ideal. Además de proporcionar información estandarizada sobre la programación, incluyen una guía de programación actualizada, algo esencial para los espectadores que saben lo que quieren ver pero no saben dónde encontrarlo. Esto resulta especialmente importante en el caso de los eventos deportivos en directo.

Con el tiempo, los modelos de lenguaje grande (LLM) ofrecerán a los espectadores experiencias televisivas revolucionarias. ¿Buscas las mejores películas de terror de 1985 por recaudación en taquilla? No hay problema. ¿Quieres recomendaciones sobre las mejores películas de fútbol según las críticas tras ver el Mundial? Es muy fácil. ¿Intentas averiguar qué servicio retransmite un partido, un programa o una película en concreto? Lo tenemos cubierto.
Las expectativas de los consumidores respecto a su interacción con la tecnología no dejan de crecer, y las plataformas de CTV tienen la oportunidad de adelantarse a los acontecimientos. Los modelos de lenguaje grande (LLM) pueden cumplir esa promesa, pero solo si se basan en datos fiables y actualizados. Dado que los telespectadores se replantean constantemente en qué invierten su tiempo y su dinero, el coste de la información no verificada o poco fiable se vuelve imposible de ignorar.
Este artículo se publicó originalmente en Streaming Media.
Notas
- Los modelos de lenguaje grande (LLM) son un tipo de IA generativa que crea contenido basándose en patrones aprendidos.
- El «grounding» es el proceso de vincular un modelo de lenguaje grande (LLM) con información del mundo real para mejorar la fiabilidad y la pertinencia de sus respuestas.
- El tiempo total dedicado a ver la televisión se ha mantenido estable en unas 33-35 horas semanales durante los últimos años; datos Nielsen Insights (Nielsen , Nielsen Impact)
Por qué los modelos de lenguaje a gran escala sin base no pueden resolver el problema del descubrimiento de contenidos
Los modelos de lenguaje a gran escala (LLM) tienen el potencial de aliviar la creciente frustración que genera la búsqueda de contenidos, pero no si ofrecen malos resultados.
Incoherencias en la IA
Sin una base sólida, los grandes modelos de lenguaje no son capaces de ofrecer resultados precisos de búsqueda y descubrimiento a los telespectadores.
El contenido deportivo de los servicios globales de SVOD pronto rivalizará con los catálogos de películas
La oferta deportiva de los proveedores de SVOD a nivel mundial supera ya los 38 500 programas.