
Von Tyler Bell, Senior Vice President Product
Da Unternehmen generative KI-Systeme wie große Sprachmodelle (LLMs1) aufgrund der damit verbundenen Effizienzsteigerungen zunehmend einsetzen, wird eine Reihe von Alttechnologien immer mehr an Bedeutung verlieren. Im Fernsehbereich werden LLMs traditionelle Datenbanken und rudimentäre Suchfunktionen ergänzen – und schließlich ersetzen. Mit der Zeit werden sie zur Standardplattform für Unterhaltungserlebnisse der nächsten Generation werden.
Diese Veränderung wird für die Verbraucher bahnbrechend sein. Fernsehzuschauer beispielsweise werden sich bei der Suche nach einem passenden Programm nicht mehr auf einfache Suchanfragen beschränken müssen.
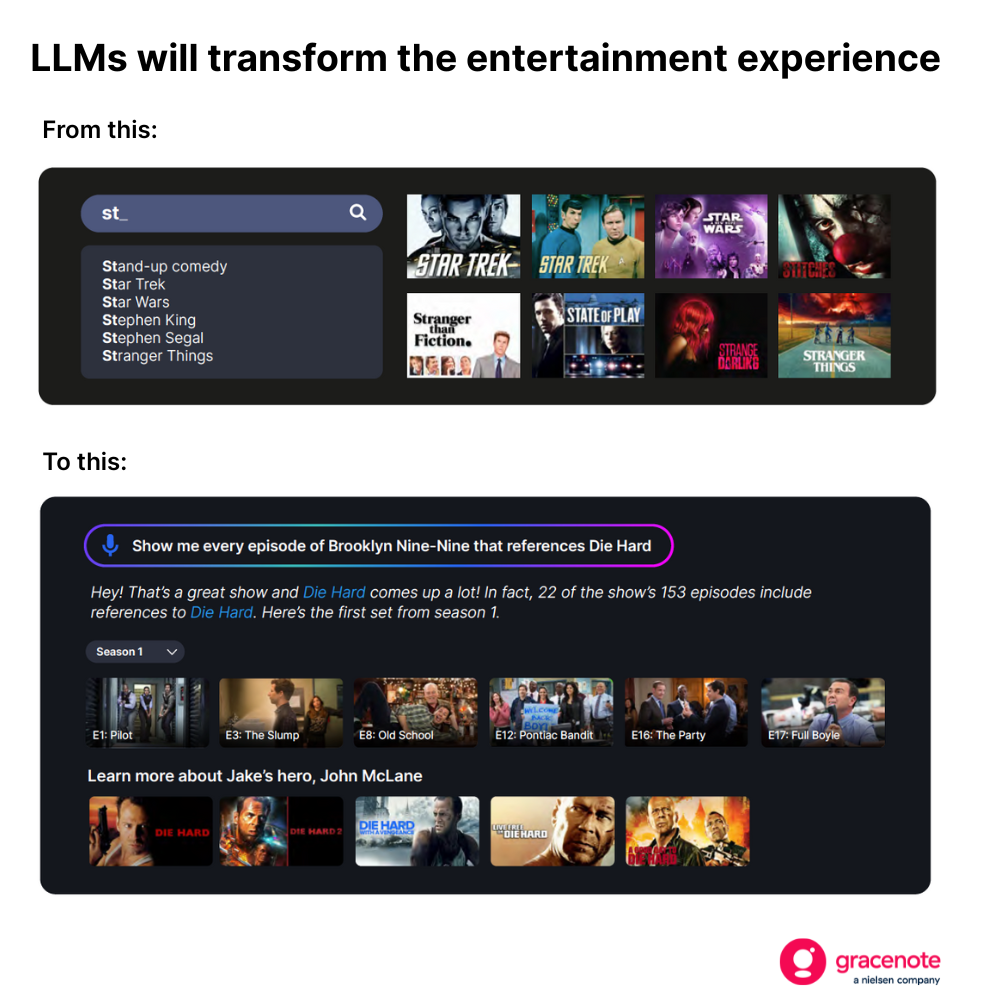
Doch um eine solche Erfahrung zu schaffen – eine, die aktuelle, genaue und relevante Ergebnisse liefert –, braucht es mehr als nur ein gut trainiertes LLM.
Das liegt daran, dass LLMs keine umfassenden Wissensdatenbanken sind. Es handelt sich um Vorhersagemodelle, die Antworten auf der Grundlage von Mustern generieren, die sie aus ihren Trainingsdaten gelernt haben. Und allzu oft sind diese Daten fehlerhaft.
Eine Studie aus dem Jahr 2022, die von Forschern der University of Southern California durchgeführt wurde, ergab, dass bis zu 38 % der als „sachlich“ geltenden Daten, die in zwei verschiedenen KI-Datenbanken verwendet wurden, verzerrt waren. Mit anderen Worten: Mehr als ein Drittel der Basisdaten in diesen Systemen war von vornherein ungenau.

Große Sprachmodelle haben auch mit relativ einfachen Aufgaben Schwierigkeiten. Im März 2025 ergab eine Studie der „Columbia Journalism Review“, dass acht generative KI-Tools eine Fehlerquote von insgesamt 60 % aufwiesen, als sie aufgefordert wurden, einen Auszug aus einem Nachrichtenartikel mit der dazugehörigen Überschrift, dem ursprünglichen Herausgeber, dem Veröffentlichungsdatum und der URL zu verknüpfen. Im Vergleich dazu lieferte eine herkömmliche Google-Suche die Quellen bereits unter den ersten drei Ergebnissen.
Die Schwächen von LLMs sind allgemein bekannt, und es gibt eine Reihe von Techniken, um Halluzinationen zu reduzieren und die kontextuelle Relevanz zu verbessern. Kaum jemand würde den Nutzen vonGrounding2 anzweifeln. Allerdings ist es ebenso problematisch, ein LLM zum Zwecke des Grounding mit ungenauen Daten zu verknüpfen, wie es problematisch ist, fehlerhafte Daten zu seinem Training zu verwenden.
Das Fazit lautet: Fehlerhafte Daten stellen eine echte Gefahr dar. Große Sprachmodelle sind leistungsstarke Werkzeuge, aber sie sind nur so gut wie die Informationen, auf die sie zugreifen können.
Einführung von LLM im Bereich CTV
Der Übergang zu LLMs wird wohl kaum in einem einzigen, einschneidenden Schritt erfolgen. Vielmehr wird er „allmählich, dann plötzlich“ stattfinden, wie Mike Campbell in Hemingways „The Sun Also Rises“ seine Insolvenz beschreibt.
Großsprachenmodelle (LLMs) sind noch eine relativ neue Technologie. Sie weisen Einschränkungen auf, erfordern die Berücksichtigung von Latenzzeiten und haben finanzielle Auswirkungen, die Unternehmen verstehen müssen, bevor sie diese in Suchoberflächen für Endnutzer implementieren. Die grundlegende Herausforderung sind jedoch die Daten.
Die meisten CTV-Schnittstellen basieren auf Data Lakes, die heterogene Metadaten aus verschiedenen Quellen enthalten. Diese müssen harmonisiert und normalisiert werden, bevor sie indexiert und für die Suche optimiert werden können. Dieser Prozess erfordert das vorherige Herunterladen großer Datensätze, deren Verarbeitung in komplexen Erfassungspipelines sowie deren kontinuierliche Aktualisierung, um die Daten auf dem neuesten Stand zu halten.
Im Gegensatz dazu zeichnen sich LLMs dadurch aus, dass sie Daten aus verschiedenen Quellen zur Laufzeit interpretieren und zusammenführen können, wodurch sich der Bedarf an herkömmlichen Data Lakes und der dazugehörigen Infrastruktur potenziell verringert – oder sogar ganz entfällt.
Gleichzeitig eröffnen LLMs dem CTV-Bereich neue Möglichkeiten und ein enormes Potenzial, das mit der derzeitigen Technologie nicht realisierbar wäre. So können LLMs beispielsweise die Beschreibung eines Films oder einer Folge dynamisch umschreiben oder ergänzen, um sie für einzelne Nutzer relevanter zu gestalten.
Wenn ein Zuschauer beispielsweise „Die Verurteilten“ gesehen hat, könnte ein LLM-Modell „The Green Mile“ mit einer maßgeschneiderten Beschreibung empfehlen: „Es handelt sich um eine Stephen-King-Verfilmung über Hoffnung, die in einem Gefängnis spielt und eine ähnliche emotionale Tiefe aufweist wie ‚Die Verurteilten‘, der Ihnen zuvor gefallen hat.“
Diese Art der kontextbezogenen Empfehlung stellt eine erhebliche Verbesserung gegenüber den allgemeinen Empfehlungen vom Typ „Weil Sie sich … angesehen haben“ dar. Große Sprachmodelle können diesen Ansatz auf alle Titel in einem Katalog anwenden.
Kurzfristig werden LLMs wahrscheinlich als Ergänzung zu bestehenden Technologien eingeführt werden und komplexe oder dialogorientierte Anfragen bearbeiten, die herkömmliche Systeme nicht bewältigen können. Im Laufe der Zeit werden einige Unternehmen ihre alten Infrastrukturen vollständig ersetzen. Letztendlich werden LLMs den Ausschlag geben.
Die Fragmentierung hat das Fernseherlebnis erschwert
Trotz des reichhaltigen Programmangebots hat die Fragmentierung der Videoverbreitung die Suche erschwert statt erleichtert, was den Anbietern von Inhalten zuwiderläuft.
Tatsächlich ergab eine aktuelle Branchenumfrage, dass fast 50 % der US-Fernsehzuschauer erwägen würden, einen Streaming-Dienst zu kündigen, weil sie nichts Passendes zum Anschauen finden. Bei den 25- bis 34-Jährigen steigt dieser Anteil sogar auf 58 %.

Mehr Inhalte bedeuten nicht zwangsläufig eine längereVerweildauer3. In der Praxis kann eine zu große Auswahl dazu führen, dass Nutzer ihre Suche ganz aufgeben und sich entscheiden, etwas anderes zu tun.
Hier können LLMs helfen – allerdings nur, wenn sie auf den richtigen Daten basieren.
Für CTV-Plattformen sind zuverlässige Unterhaltungsdaten nach Branchenstandard eine ideale Informationsquelle. Neben standardisierten Programminformationen umfassen sie aktuelle Fernsehprogramme, die für Zuschauer unverzichtbar sind, die zwar wissen, was sie sehen möchten, aber nicht, wo sie es finden können. Dies ist besonders bei Live-Sportübertragungen von entscheidender Bedeutung.

Mit der Zeit werden große Sprachmodelle den Zuschauern bahnbrechende TV-Erlebnisse ermöglichen. Suchen Sie nach den erfolgreichsten Horrorfilmen des Jahres 1985, gemessen an den Einspielergebnissen? Kein Problem. Möchten Sie nach der Weltmeisterschaft Empfehlungen für die besten Fußballfilme basierend auf Kritiken erhalten? Ganz einfach. Möchten Sie herausfinden, welcher Dienst ein bestimmtes Spiel, eine bestimmte Sendung oder einen bestimmten Film anbietet? Kein Problem.
Die Erwartungen der Verbraucher an die Interaktion mit Technologie steigen weiter, und CTV-Plattformen haben die Chance, sich einen Vorsprung zu verschaffen. Große Sprachmodelle (LLMs) können dieses Versprechen einlösen – allerdings nur, wenn sie auf vertrauenswürdigen, aktuellen Daten basieren. Da Fernsehzuschauer ständig neu überdenken, wofür sie ihre Zeit und ihr Geld ausgeben, lassen sich die Kosten ungeprüfter oder unzuverlässiger Informationen nicht mehr ignorieren.
Dieser Artikel erschien ursprünglich auf Streaming Media.
Anmerkungen
- LLMs sind eine Art generativer KI, die Inhalte auf der Grundlage erlernter Muster erstellt.
- Grounding ist der Prozess, bei dem ein LLM mit Informationen aus der realen Welt verknüpft wird, um die Zuverlässigkeit und Relevanz seiner Antworten zu verbessern.
- Die Gesamtzeit, die vor dem Fernseher verbracht wird, ist in den letzten Jahren mit 33 bis 35 Stunden pro Woche unverändert geblieben; Daten Nielsen Insights (Nielsen , Nielsen Impact)
Warum nicht auf Daten basierende große Sprachmodelle das Problem der Inhaltssuche nicht lösen können
Große Sprachmodelle (LLMs) haben das Potenzial, die wachsende Frustration bei der Suche nach Inhalten zu lindern – allerdings nur, wenn sie gute Ergebnisse liefern.
Handlungslücken in der KI
Ohne eine solide Grundlage sind große Sprachmodelle nicht in der Lage, den Fernsehzuschauern präzise Such- und Entdeckungsergebnisse zu liefern.
Sportinhalte auf globalen SVOD-Diensten werden bald mit Filmkatalogen konkurrieren
Das Sportangebot der weltweiten SVOD-Anbieter umfasst mittlerweile mehr als 38.500 Sendungen.