
بقلم تايلر بيل، نائب الرئيس الأول للمنتجات
مع تبنّي الشركات لأنظمة الذكاء الاصطناعي التوليدي، مثل نماذج اللغة الضخمة (LLMs1)، لما توفره من كفاءة، ستصبح مجموعة من التقنيات القديمة قديمة بشكل متزايد. في مجال التلفزيون، ستعزز نماذج اللغة الضخمة قواعد البيانات التقليدية ووظائف البحث البدائية، وستحل محلها في نهاية المطاف. مع مرور الوقت، ستصبح هذه النماذج المحركات الافتراضية لتقديم تجارب ترفيهية من الجيل التالي.
سيشكل هذا التحول نقطة تحول جذرية بالنسبة للمستهلكين. فعلى سبيل المثال، لن يقتصر جمهور التلفزيون بعد الآن على استعلامات البحث الأساسية عند البحث عن شيء لمشاهدته.
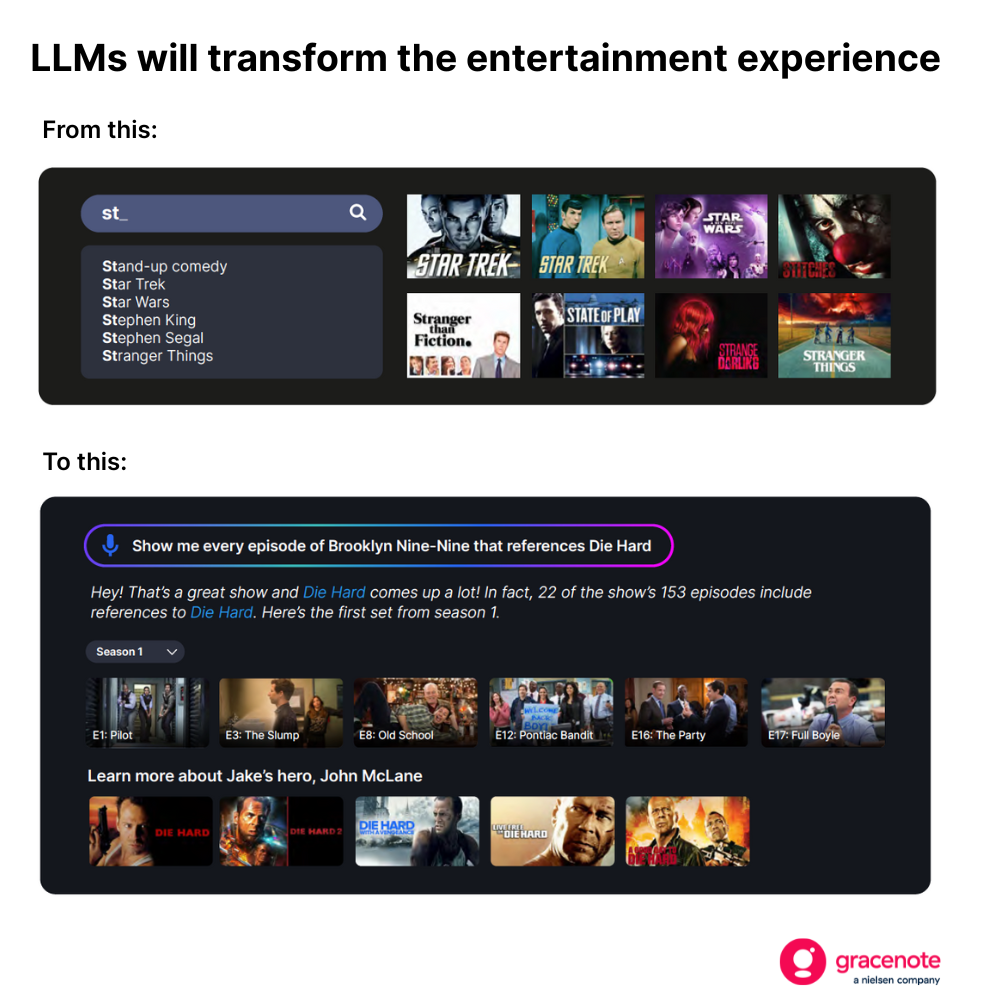
لكن بناء هذا النوع من التجارب — التي تقدم نتائج حديثة ودقيقة وذات صلة — يتطلب أكثر من مجرد نموذج لغة كبيرة (LLM) مدرب جيدًا.
وذلك لأن نماذج اللغة الكبيرة (LLMs) ليست بنوك معرفة شاملة. إنها محركات تنبؤية تُنتج ردودًا استنادًا إلى الأنماط التي تعلمتها من بيانات التدريب الخاصة بها. في كثير من الأحيان، تكون تلك البيانات مغلوطة.
كشفت دراسة أجريت عام 2022 من قبل باحثين في جامعة جنوب كاليفورنيا أن ما يصل إلى 38% من البيانات «الواقعية» التي تعتمد على المنطق السليم، والمستخدمة في قاعدتي بيانات منفصلتين للذكاء الاصطناعي، كانت متحيزة. بعبارة أخرى، كان أكثر من ثلث البيانات الأساسية في هذين النظامين غير دقيقة منذ البداية.

كما تواجه نماذج اللغة الكبيرة (LLMs) صعوبات في أداء مهام بسيطة نسبيًا. ففي مارس 2025، كشفت دراسة أجرتها مجلة «كولومبيا جورناليزم ريفيو» أن ثماني أدوات للذكاء الاصطناعي التوليدي سجلت معدل خطأ إجمالي بلغ 60% عندما طُلب منها ربط مقتطف من مقال إخباري بالعنوان المقابل له، والناشر الأصلي وتاريخ النشر وعنوان ال URL. بالمقارنة، أظهر البحث التقليدي على جوجل المصادر ضمن النتائج الثلاثة الأولى.
إن أوجه القصور في نماذج اللغة الكبيرة (LLMs) معروفة على نطاق واسع، وهناك مجموعة من التقنيات المتاحة للحد من «اختلاف محتوى المصدر» وتحسين ملاءمة السياق. قليلون هم من يجادلون في قيمة«التأسيس»2. مع ذلك، فإن ربط نموذج لغة كبير ببيانات غير دقيقة من أجل «التأسيس» يمثل مشكلة لا تقل خطورة عن استخدام بيانات مغلوطة لتدريبه.
الخلاصة هنا هي أن البيانات الرديئة تشكل تهديدًا حقيقيًا. تعد نماذج اللغة الكبيرة (LLMs) أدوات قوية، لكن جودتها تعتمد كليًا على جودة المعلومات التي يمكنها الوصول إليها.
تطبيق تقنية LLM في مجال التلفزيون المتصل بالإنترنت
من غير المرجح أن يتم الانتقال إلى نماذج اللغة الكبيرة (LLMs) في خطوة واحدة جذرية. بل سيحدث ذلك «تدريجيًا، ثم فجأة»، كما يصف مايك كامبل، أحد شخصيات رواية «الشمس تشرق أيضًا» لهمنغواي، إفلاسه.
لا تزال نماذج اللغة الكبيرة (LLMs) تقنية حديثة نسبيًا. فهي تنطوي على قيود واعتبارات تتعلق بزمن الاستجابة وتبعات مالية يجب على المؤسسات فهمها قبل تطبيقها في واجهات البحث الموجهة للمستهلكين، لكن التحدي الأساسي يكمن في البيانات.
تستند معظم واجهات CTV إلى بحيرات بيانات تحتوي على بيانات وصفية متنوعة من مصادر متعددة، والتي يجب مواءمتها وتوحيدها قبل فهرستها وتحسينها لأغراض البحث. تتطلب هذه العملية تحميل مجموعات بيانات ضخمة مسبقًا، وتمريرها عبر مسارات استيعاب معقدة، وتحديثها باستمرار للحفاظ على حداثة البيانات.
على النقيض من ذلك، تتفوق نماذج اللغة الكبيرة (LLMs) في تفسير البيانات الواردة من مصادر متعددة ومواءمتها أثناء التشغيل، مما قد يقلل - أو حتى يلغي - الحاجة إلى بحيرات البيانات التقليدية والبنية التحتية المرتبطة بها.
وفي الوقت نفسه، توفر نماذج اللغة الكبيرة (LLMs) إمكانيات جديدة وهائلة لتقنية التلفزيون المتصل بالإنترنت (CTV)، وهو ما كان سيستحيل تحقيقه باستخدام التكنولوجيا الحالية. فعلى سبيل المثال، يمكن لنماذج اللغة الكبيرة إعادة صياغة أو توسيع وصف فيلم أو حلقة تلفزيونية بشكل ديناميكي ليكون أكثر ملاءمة للمستخدمين الأفراد.
على سبيل المثال، بعد أن يشاهد أحد المشاهدين فيلم «The Shawshank Redemption»، يمكن لنظام التعلم الآلي (LLM) أن يوصي بفيلم «The Green Mile» مصحوبًا بوصف مخصص يقول: «إنه فيلم مقتبس عن رواية لستيفن كينغ يتناول موضوع الأمل، وتدور أحداثه في سجن، ويتميز بعمق عاطفي مشابه لفيلم «The Shawshank Redemption» الذي استمتعت بمشاهدته سابقًا.»
تمثل هذه النوعية من التوصيات السياقية تحسناً ملحوظاً مقارنةً بالتوصيات العامة من نوع «لأنك شاهدت». يمكن لنماذج اللغة الكبيرة (LLMs) تطبيق هذا النهج على جميع العناوين الموجودة في الكتالوج.
على المدى القريب، من المرجح أن يتم إدخال نماذج اللغة الكبيرة (LLMs) لتكمل التقنيات الحالية، حيث ستتولى معالجة الاستفسارات المعقدة أو التخاطبية التي تعجز الأنظمة التقليدية عن معالجتها. مع مرور الوقت، ستقوم بعض المؤسسات باستبدال بنيتها التحتية القديمة بالكامل. في نهاية المطاف، سترجح الكفة لنماذج اللغة الكبيرة (LLMs).
أدى التجزؤ إلى تعقيد تجربة مشاهدة التلفزيون
على الرغم من وفرة البرامج المتاحة، فإن تجزئة توزيع الفيديو جعلت العثور على المحتوى أكثر صعوبة، لا أسهل، مما يضر بمصالح مزودي المحتوى.
في الواقع، أظهر استطلاع حديث أجرته إحدى الشركات في هذا القطاع أن ما يقرب من 50% من مشاهدي التلفزيون في الولايات المتحدة قد يفكرون في إلغاء اشتراكهم في إحدى خدمات البث المباشر لأنهم لا يجدون ما يشاهدونه. وترتفع هذه النسبة إلى 58% بين المشاهدين الذين تتراوح أعمارهم بين 25 و34 عامًا.

زيادة المحتوى لا تعني بالضرورة زيادةوقت المشاهدة3. وفي الواقع، قد يؤدي كثرة الخيارات إلى دفع المشاهدين إلى التخلي عن عمليات البحث تمامًا واللجوء إلى نشاط آخر.
وهنا تكمن فائدة نماذج اللغة الكبيرة (LLMs) — ولكن فقط عندما تستند إلى البيانات الصحيحة.
بالنسبة لمنصات CTV، تُعد البيانات الترفيهية الموثوقة والمتوافقة مع معايير القطاع مصدرًا أساسيًا مثاليًا. فإلى جانب توفير معلومات موحدة عن البرامج، تتضمن هذه البيانات قوائم برامج تلفزيونية محدثة، وهي أمر ضروري للجمهور الذي يعرف ما يريد مشاهدته ولكنه لا يعرف أين يجده. ويكتسب هذا الأمر أهمية خاصة في حالة البث المباشر للأحداث الرياضية.

مع مرور الوقت، ستتيح نماذج اللغة الكبيرة (LLMs) للمشاهدين تجارب تلفزيونية ثورية. هل تبحث عن أفضل أفلام الرعب لعام 1985 من حيث إيرادات شباك التذاكر؟ لا مشكلة. هل تريد توصيات بأفضل أفلام كرة القدم بناءً على تقييمات النقاد بعد مشاهدة كأس العالم؟ الأمر سهل. هل تحاول معرفة أي خدمة تبث مباراة أو برنامجًا أو فيلمًا معينًا؟ لا تقلق، الأمر تحت السيطرة.
تستمر توقعات المستهلكين بشأن طريقة تفاعلهم مع التكنولوجيا في الارتفاع، وتُتاح لمنصات التلفزيون المتصل بالإنترنت (CTV) فرصة للبقاء في الطليعة. ويمكن لنماذج اللغة الكبيرة (LLMs) أن تفي بهذا الوعد – ولكن فقط عندما تستند إلى بيانات موثوقة ومحدثة. ومع قيام مشاهدي التلفزيون بإعادة تقييم الأماكن التي يقضون فيها وقتهم وينفقون أموالهم باستمرار، يصبح من المستحيل تجاهل تكلفة المعلومات غير المدققة أو غير الموثوقة.
نُشرت هذه المقالة في الأصل على موقع " Streaming Media".
الملاحظات
- نظم اللغة الكبيرة (LLMs) هي أنواع من الذكاء الاصطناعي التوليدي التي تُنشئ محتوى استنادًا إلى الأنماط التي تعلمتها.
- التأسيس هو عملية ربط نموذج اللغة الكبيرة (LLM) بالمعلومات الواقعية من أجل تحسين موثوقية إجاباته ومدى ملاءمتها.
- ظل إجمالي الوقت الذي يقضيه المشاهدون أمام التلفزيون ثابتًا عند 33-35 ساعة أسبوعيًا خلال السنوات القليلة الماضية؛ وفقًا لبيانات " Nielsen إنسايتس" (Nielsen Nielsen Impact)
لماذا لا تستطيع نماذج اللغة الكبيرة غير المرتبطة ببيانات معينة حل مشكلة اكتشاف المحتوى
تتمتع نماذج اللغة الكبيرة (LLMs) بالقدرة على التخفيف من الإحباط المتزايد بشأن اكتشاف المحتوى — ولكن ليس إذا قدمت نتائج سيئة.
ثغرات في منطق الذكاء الاصطناعي
بدون أساس سليم، لا تستطيع النماذج اللغوية الضخمة تقديم نتائج بحث واكتشاف دقيقة لمشاهدي التلفزيون.
سيصبح المحتوى الرياضي على خدمات البث حسب الطلب العالمية منافسًا قويًا لمجموعات الأفلام قريبًا
يتجاوز عدد البرامج الرياضية المتوفرة عبر مزودي خدمات الفيديو حسب الطلب (SVOD) العالميين الآن 38.5 ألف برنامج.